[论文笔记] FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning (2023.07)
FlashAttention-2 是基于 FlashAttention 的改进版,运算效率得到了约 2x 提升。下面是本文的阅读笔记。
动机
虽然 FlashAttention 通过减少 IO 搬运,大幅提升了运算速度以及减少显存占用,但并没有完全发挥GEMM运算的理论速度,只达到了理论FLOPs的25-40%。其原因在于GPU上不同 thread blocks 和 warps 分配不够优秀,核心占用率偏低且存在不必要的内存读写。因此 FlashAttn-2 进行了三点优化:
- 调整算法,减少非矩阵乘法的运算量。在 GPU 上有专门的 GEMM 计算单元,吞吐量可高达其他算子的 16 倍。
- 在序列长度维度上,将注意力计算并行分配到不同 thread block 上;
- 在线程块内实现 warps 并行,减少共享内存通信。
背景
硬件简介
执行模型:GPU 内部有许多线程(即内核 kernel)。线程被组织成线程块(thread blocks)在 SM (streaming multiprocessors) 上运行。每个 block 内的线程被分组成 warps(线程束),即32个线程。同一个 warps 内的线程可以快速交换数据进行通信。同一个 block 的不同 warps 可以读写 shared memory 进行通信。
FlashAttention-2的改进
减少 non-matmul FLOPS:
- 在计算 online softmax 的过程中,不再存储缩放后的 ,即 ,而是存储一个没有缩放后的输出值(只有分子上的 部分);这样可以避免在每次更新 时,都需要先乘以 以把输出值还原成分子,从而带来没有必要的 non-matmul 计算
- 在反向传播过程中,不再分别存储 和 ,只需要存
下面是更新后的 online softmax 算法,主要反映了刚才所述的第一点:
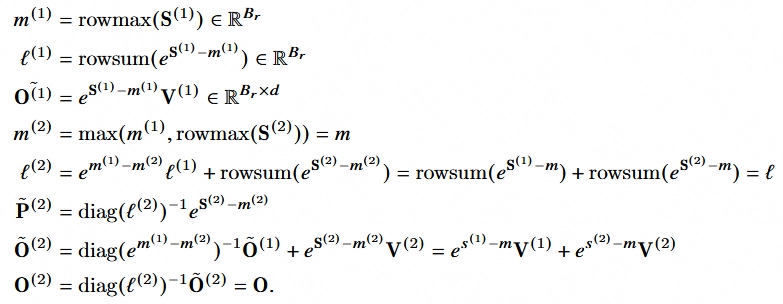
对应的前向传播伪代码如下:

可以看到,online softmax 的改进已经体现在算法中。现在只会在内层循环完成以后,才会将 除以 ,而不是在中间提前计算完成。
此外还有一处改变:内层循环与外层循环的变量调换了位置,现在外层循环的目标是行数。由于每行之间的计算结果相互独立,因此最外层循环可以在 kernel 上并行起来,增加并行程度。
并行性分析
FA1:同时在batch size与nhead维度上进行并行,但在长序列条件下,对GPU的利用率不高
FA2:在FA1的基础上,将序列维度的循环提前到外层循环;这样就可以在序列维度上并行起来;反向传播时类似,也可以在序列长度维度上进行并行
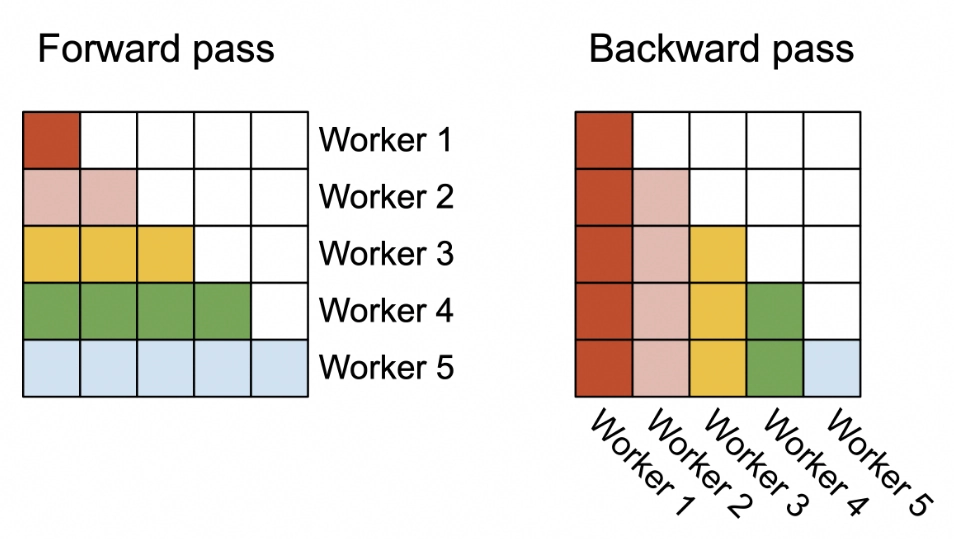
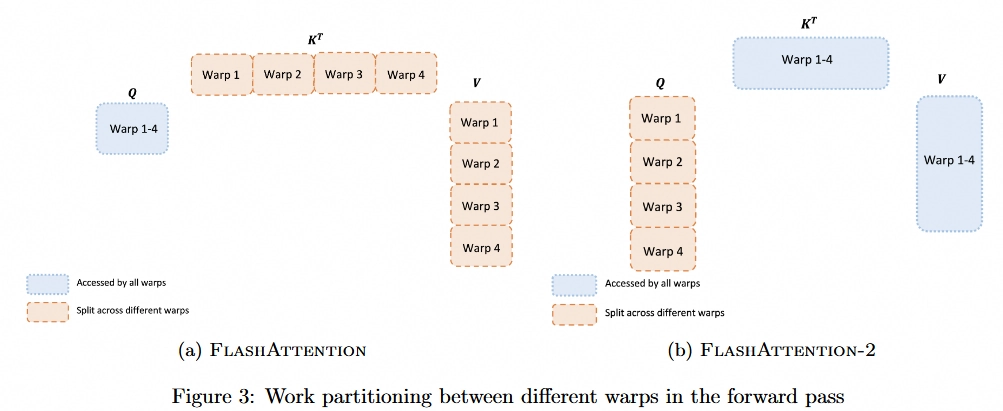
warp并行分析:FA1中,虽然也可以以外层循环为维度进行并行(split-K),但并行过程中,不同warps之间产生写入冲突,降低IO效率;因此FA2中对这一点进行了改进,将其改成 split-Q,这样不同warps会写入至不同的位置,避免由于IO锁降低效率。
效果
与FA1相比, 比 pytorch 版快1.7-3.0倍,比 triton 版快1.3-2.5倍。比标准注意力实现快3-10倍。
~2x 加速,达到理论峰值的 50-73%。